How We’re Building Computers Out Of DNA And Proteins
March 2020
You read the title correctly. We’ve heard of classical and quantum computing, but promising research and work suggest that future supercomputers will consist of biological components.
Biocomputing, or organic computing, is an emerging field of computation that’s completely different from anything we’ve seen before the 21st century — and the area is still rapidly emerging.
So what specifically is biocomputing, and how does it work?
Biocomputing refers to computation using DNA or other organic structures.
The word biocomputing is pretty self-explanatory — computing systems that use biological materials. While computational biology means modeling biology on computers, with biocomputing, biology becomes building blocks for computers. We’re now entering the world of wetware.
This probably sounds pretty abstract and implausible, and while the technology is experimental and theoretical, we know it can work.
Three main sectors of biocomputing right now:
- Nano-biological motors: natural/synthetic living materials in parallel computational circuits 🔌
- DNA computing: design computational wetware from the genome 🧬
- DNA-based data storage 🤯
Before we dive into each of these points, it’s important to internalize that computation has always existed on a cellular level. DNA stores the core data of who we are in the form of base pairs -> RNA inputs data -> ribosomes perform logic operations -> outputs are in the form of synthesized proteins.
In a way, our bodies function as computers — with biocomputing we extrapolate and model these processes physically, outside of nature.
Nano-biological motors are being leveraged for parallel computation.
Through leveraging molecular machines at the nanoscale, past experiments and research have shown how these ‘nano-biological’ motors are the future of parallel computation.
With ordinary computers (like the one you’re using now 😉), tasks are done sequentially. Multiple tasks done simultaneously are actually lightning-fast switches between tasks within your processor. To exponentially increase the capabilities of our computers, parallel computing is necessary — multiple tasks truly being done simultaneously.
Parallel computing through nano-biological motors could be our new approach. Not only is there the potential for more complex computation, but cost and energy efficiency are also possible. In fact, nano-biological motors use 1% of the energy consumed by modern electronic transistors.
So how do they actually work?
The key ingredients: proteins and artificial labyrinthine structures.
Extremely small maze structures are built out of artificial components, with pathways and exits representing answers to computational problems/tasks. Myosin guides protein filaments alongside artificial pathways — thus motors moving through a maze, with their solution representing the answer to a computational problem.
.gif)
These biocomputers are the size of a book, with the same computational power for mathematical problems as a supercomputer. Additionally, this model was able to solve the ‘Subset Sum Problem’ faster than classical, sequential computers. The advantages are clear — all because of parallel computing!
Check it out!

DNA also has the potential to solve computational tasks and problems.
Nano-biological molecular machines that move through computational mazes are cool, but DNA (deoxyribonucleic acid) has also shown high potential for computation. With DNA computing, silicon chips are replaced with strands of DNA.
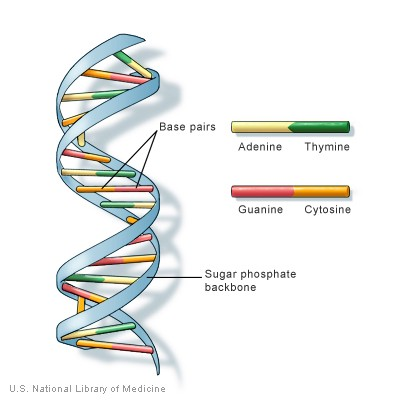
Quick refresh: in strands of DNA, the building blocks of all organisms, information is represented using A’s, G’s, C’s, and T’s -> Adenine, Guanine, Cytosine, and Thymine. These are called nucleotides or bases. Pairs of letters in double-helical DNA are referred to as base pairs.
DNA Computing with Algorithms
In DNA Computing, an algorithm’s input is represented as a sequence of DNA. Instructions are then carried out by lab procedures on DNA, like gene editing. The result (answer to the computational problem) is some property of the final DNA molecule.
The most prevalent example of DNA computing in action is Adleman’s Experiment — following the aforementioned process, DNA molecules were used to solve the Travelling Salesman problem.
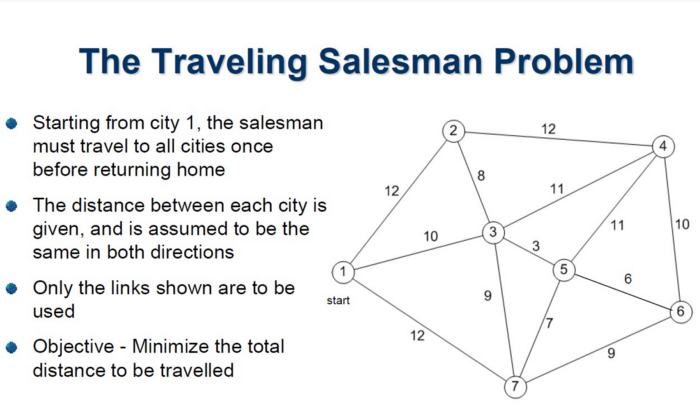
Adleman’s experiment opened up the possibility of programmed biochemical reactions. However, this was only on a small scale -> as problem complexity increases, so will DNA volume. But most importantly, the idea of DNA for parallel computation checks out — biological components can act on DNA strands simultaneously, enabling parallel computing.
Self-Assembly and Programmability
Strands of DNA also show promise to become programmable in terms of self-assembly, structure, and behavior — like computer-based robotic systems. Programmable biochemical systems that can sense surroundings, act on decisions and more are being developed. That being said, this isn’t necessarily artificial intelligence. Instead, DNA molecules execute these functions based on reactions from stimuli/interaction.
A huge area in this field is DNA Origami -> the ability for single (1D) strands of DNA to form into 2D shapes and sheets, and then self-assemble into 3D scaffolds.
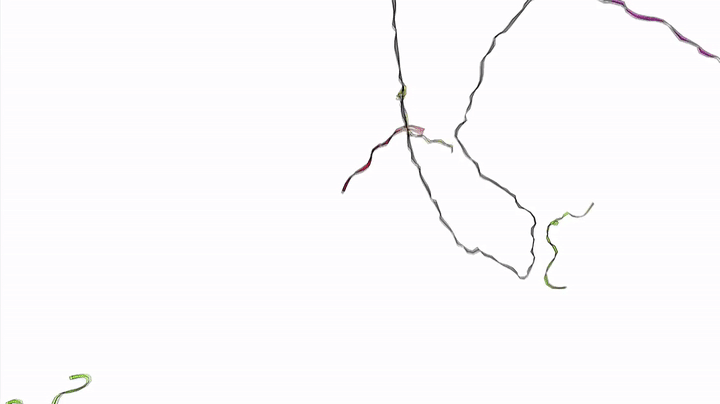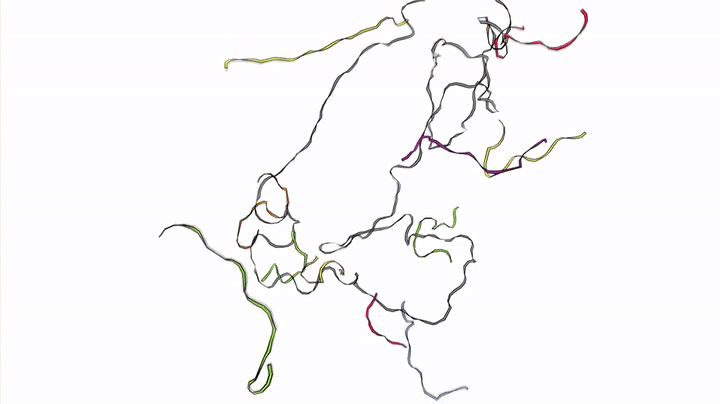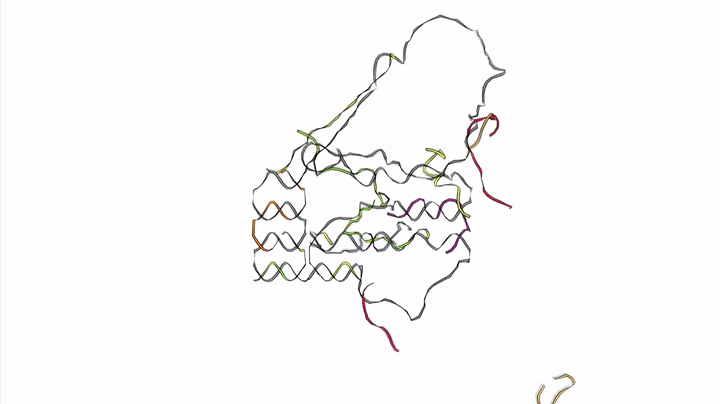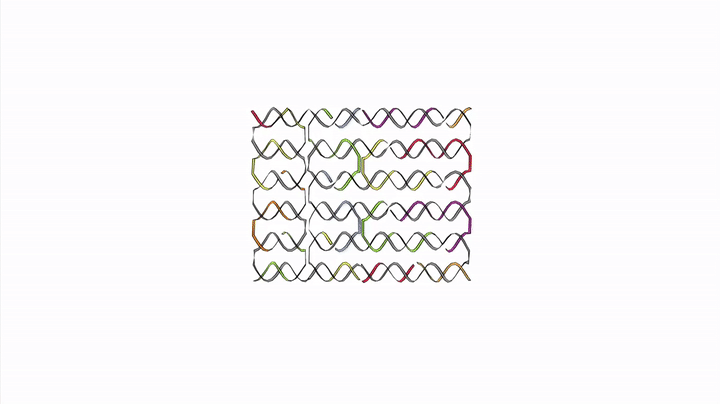
Biochips — DNA Computing through Self-Multiplication
In short, silicon transistors and chips are becoming obsolete. They’ve reached their maximum potential for optimal size and computational capabilities. Functionally, our silicon tech has met their atomic limit. Biocomputing to the rescue!
DNA sequences are the building blocks of ‘biochips’ — demonstrating their direct potential to replace silicon chips. Millions of DNA strands multiply themselves in number iteratively to perform calculations. With biochips, as opposed to Adleman’s experiment, DNA computes through self-multiplication instead of editing within a lab.
Think of a hydra — when you cut off one of their heads, two more grow back. By the same token, these genetic sequences expand as more computation is performed. Therefore, DNA computers expand as they solve computational problems and tasks.

In summary — DNA has the potential to pioneer small-scale and effective computation.
DNA is the future of digital data storage.
In my opinion, this is the cream of the crop when it comes to biocomputing. Not just because of coolness, but because of its potentially massive implications.
Technology is at the forefront of society — whether for education, finances, entertainment, or dating. While obviously providing several benefits, an issue is exponentially growing on a daily basis — data generation. With over 80% of America owning a smartphone (not to even mention the rest of the world), our tech usage rapidly generates and creates data. Despite controversy around topics of data collection, a key problem lies with this phenomenon — we don’t have enough storage.
In fact, conservative estimates predict that by 2025, data storage systems will only be able to store half of our generated data.
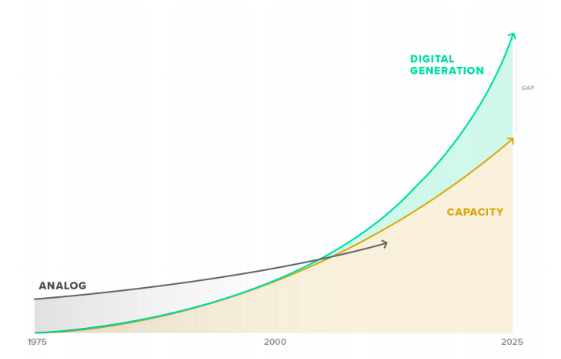
Building more hard drives and expanding AWS aren’t the best solutions to the problem, economically and feasibly. Ideally, data needs to be densely stored at an extremely small scale.
If DNA already stores data in the form of nucleotides in organisms… and is very small… what better way to tackle this issue? Introducing DNA Data Storage.
DNA is extremely small, stable, and will never be obsolete — they’ve existed since the beginning of life.
A single nucleotide can take up four values, so they’re analogous to two binary bits:
- A -> 01
- G -> 10
- C -> 00
- T -> 11
A typical human cell has 6 billion base pairs in the form of a double helix, organized in chromosomes. Scientists estimate that a single cell of DNA can encode 1.6 gigabytes — which scales to 100 zettabytes in the entire human body. For context, 100 zettabytes are more than humans have collectively generated throughout time.
Meaning, by leveraging DNA — we could store all the data the world has generated throughout history. And it would take up the amount of space as a human body.
Digital DNA Data Storage is a 6-step Process
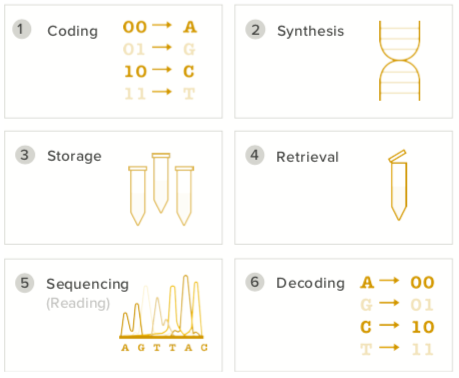
Encoding: the binary data that needs to be stored on the DNA sequence is converted to nucleotide values.
Synthesis: our encoded DNA sequence is actually designed and made through synthetic biology/gene engineering
Storage: the encoded DNA is stored for later usage
Retrieval: when it’s needed, DNA is retrieved
Sequencing: the DNA is sequenced or ‘read’, reading and writing the molecule’s nucleotide sequence
Decoding: the sequenced DNA (list of A’s, G’s, C’s and T’s) is converted back into binary and is readable by a classical computer.
The process for data storage may seem complex, but as sequencing and synthesis technologies continue to improve over time, this framework will eventually become very simple. Right now, Twist Bioscience uses silicon as a substrate for DNA synthesis. They own a novel platform for manufacturing synthetic DNA on a massive, parallel scale — leaving little boundaries for effective and efficient DNA data storage.
Most importantly, the advantages of DNA are clear and powerful:
- high storage density
- can be 3D, as opposed to 2D disks or chips
- can last centuries/millennia before maintenance is required
- large demand and economic impact
Material costs of less than a fraction of a penny per gigabyte of stored data, is estimated for the encoding and decoding for DNA. Compared to average USB costs of $3/gb, the overwhelming benefits are clear.
And that’s Biocomputing!
The race has just begun to discover and identify ways DNA + other molecular structure can revolutionize computation. Experimentation and research has been done, so we know ‘it works’ — but to truly build super-bio-computers we need exponentially more awareness and people working in this field.
While the theory in itself is awesome, there’s genuine massive potential economically and computationally through biology.
Biocomputing suggests several advantages over quantum and classical computation.
While the idea of futuristic computers made from cellular components is extremely interesting, there’s a genuine opportunity for biocomputing in the world of computation. DNA is highly stable and in contrast to quantum computing, doesn’t need to be stored at unnatural temperatures for functionality. In the case of digital DNA storage, we anticipate centuries before error-correction processes are necessary.
The overwhelming advantage is how better computation can be achieved on a radically smaller scale. As opposed to bulky classical supercomputers and quantum computers, at the size of a book or human body, we can satisfy the computational and storage needs of the entire world’s population.
Crazy.
Key Takeaways
- Biocomputing -> computers partly or wholly made of biological materials
- Proteins and DNA sequences are being leveraged for effective and small-scale comptuation, specifically with solving problems and storing data
- Nano-biological motors -> using myosin to guide protein filaments within mazes for computation
- The economic potential of biocomputing is massive, and can solve world issues like data storage